Obviously the SSC readership is a very long way from being an unbiased sample of (say) the whole world's population. No one would expect it to be, and in fact that's the point here: a survey of people who are obviously unusual in some respects (whatever combination of quirks turns someone into a likely SSC reader) turns out to be unusual in another respect with no obvious connection, namely having substantially more firstborn children than you'd expect.
Whatever it is that makes someone more likely to read SSC, it seems like it's probably a combination of things that surely can't correlate with birth order (e.g., being a native English speaker) and, broadly speaking, personality traits (e.g., being interested in the sort of thing Scott writes).
So the results show evidence of a link between birth order and personality, and (from the survey results) apparently a strong one. Which is interesting if true. And all of this only works because the SSC readership is far from typical of the population of a whole.
So, again, what do you mean by "skewed"? And why is it a problem?
Did you even look at the graphic I linked to? If so, there’s no need to “go look” at anything, since that graphic very clearly shows there’s not a major difference.
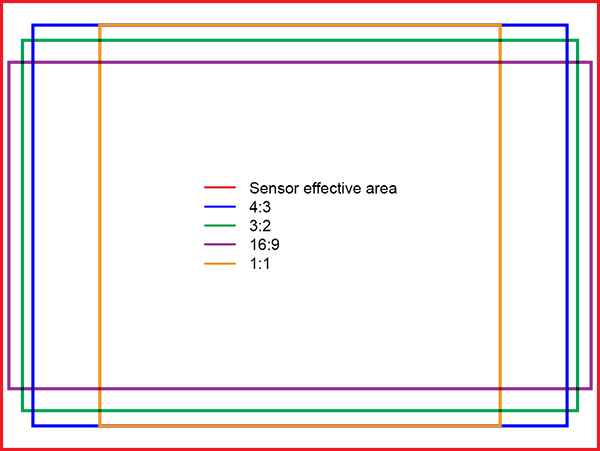
If you're doing primarily vertical tasks (coding, web pages, etc.), the taller aspect ratio can be really helpful.
That said, I've mostly made my peace with 16:9. Write shorter functions (that's good anyway) and throw bars over to the side instead of top and bottom.
Screen sizes are reported on the diagonal, but the makers are not constrained to maintain the same diagonal size with different apsect ratios. For instance, the pixel Chromebooks have 12.82" and 12.3" diagonal screens. I've never seen a 16:9 laptop with those sizes.
And specifically for an xps 13 device, where they trim excess bezels, etc., the keyboard width becomes the limiting factor.
The graphic you linked shows the different aspect ratios available to cameras from Panasonic's LX series. If there's "not a major a difference" then why is the LX series so highly regarded for this feature?
Just a bit more vertical space (a few? a dozen? more lines of code per screen) vs slightly wider screen (better for movies, and games maybe). It may be nitpicking, I actually grew used to 16:9 aspect ratios and don't really mind it.
i find 16:9 allows me to comfortably fit a text editor (with tree browser, minimap, and 100 columns of text) on the left and a terminal on the right. i need to shrink the text further than is comfortable for me if i want that layout on most 3:2 displays.
More vertical space = better for reading code. Still wide enough to split. I generally use 3 vertical splits (or sometimes more), so I'm personally not convinced, but that's the argument.
I’d also like to comment on the “ha, fooled you!” tactic used in this article, where the authors asks the reader to choose the photo of the real person from two given photos and then reveals that, gasp, both are computer generated.
Whenever I run into this often-used tactic in papers and talks, I can’t help but feel – no, the author didn’t just convince me of their point. Instead they convinced me that they don’t value being trustworthy. Often I will just stop reading the article right then. Or if I do continue I will become unforgivingly skeptical of any claim that doesn’t provide a citation that is independently verifiable.
Use of the tactic feels particularly peculiar in an article which itself grasps towards the implications of a future in which photos and videos are no longer trustworthy, a future in which personal reputation will be more meaningful.
maybe so (they fooled me) but you were already prepped to scrutinize them. To the point others have made, we’ll soon need to be constantly prepared to assume fakery.
the technology of fakery is rising the meet the “everything is fake news” moment
I immediately picked the right image, because I saw whisker stubble on the left, and I already knew that image-generation AIs seem to have a thing for painting whisker stubble all over anything even remotely resembling a male face.
Surprise! Guess I should have considered the possibility of a trick question.
I think "scanning" would imply compositing info gathered at different instances of time to reconstruct 3-D models ... e.g., LIDAR captures a point cloud with points measured at different times and tries to reconstruct objects from that point cloud. Perhaps the time it takes LIDAR to gather the whole point cloud is small, but objects will drift during that time and the reconstruction algorithm might need to account for this. On the other hand, the article's method captures all info in one instantaneous image and reconstructs based on the known, recorded, bias of the irregular lens and the implied 3-D locations of objects.
{kind=link}
{kind=link}
https://goo.gl/forms/8bmb7dwWyBtS5nDM2
And it is pretty obvious the sample is bias, though take a look to see for yourself and comment if you notice anything too.