I’ve come to think of interviews with people like Sam Altman as “freestyle science fiction.” They’re just saying stuff off the top of their head. Like you say, that often entails vague ideas from other sci fi percolating up and out, with no consideration of if they actually make sense. And like most freestyle, it’s usually pretty bad.
That is possible because DOGE and their comrades gutted the SEC and indirectly FINRA like a fish. The government is run by confidence men running crypto scams.
That’s how the CFO of OpenAI can essentially say “we need a Federal bailout”, and then turn around and say “lol just joking”.
I'd say they're basically floating on the success of previous sci-fi ideas that they made a reality; reusable rockets at a fraction of the price of NASA or ESA launches for example, or self-driving electric cars (the electric part was a success, the self-driving, not so much).
That post does not appear to address or acknowledge any of these problems: 1) thermal management in space, 2) radiation degrading the onboard silicon, 3) you can’t upgrade data centers in orbit
I feel like I’ve seen more and more people recently fall for this trick. No, LLMs are not “empathetic” or “patient”, and no, they do not have emotions. They’re incredibly huge piles of numbers following their incentives. Their behavior convincingly reproduces human behavior, and they express what looks like human emotions… because their training data is full of humans expressing emotions? Sure, sometimes it’s helpful for their outputs to exhibit a certain affect or “personality”. But falling for the act, and really attributing human emotions to them seems, is alarming to me.
There’s no trick. It’s less about what actually is going on inside the machine and more about the experience the human has. From that lens, yes, they are empathetic.
Technically they don't have incentives either. It's just difficult to talk about something that walks, swims, flies, and quacks without referring to duck terminology.
It sounds like a regrettable situation: whether something is true or false, right or wrong, people don’t really care. What matters more to them is the immediate feeling. Today’s LLM can imitate human conversation so well that they’re hard to distinguish from a real person. This creates a dilemma for me: when humans and machines are hard to tell apart, how should I view the entity on the other side of the chat window? Is it a machine or a human? A human。
Sounds like you aren't aware that a huge amount of human behaviors that look like empathy and patience are not real either. Do you really think all those kind-seeming call-center workers, waitresses, therapists, schoolteachers, etc. actually feel what they're showing? It's mostly an act. Look at how adults fake laughter for an obvious example of popular human emotion-faking.
Its more than that, this pile of numbers argument is really odd. I feel its hard to square this strange idea that piles of numbers are "lesser" than humans unless they are admitting belief in the supernatural .
The authors point is not that these things are “slop” in and of themselves, it’s that the demand for each of these so outpaces supply that the market is full of low quality (sometimes fraudulent) knock offs. AKA… slop.
Thinking about the “overall economy” increasingly means focusing on the spending of the rich, and ignoring the poor and struggling. A consequence of increasing inequality is the rich make up more and more consumer spending. Consumer spending can therefore easily look great while most people are struggling to get by. There really is no “overall economy”, there are many many different stories happening all at once, and focusing on simple metrics lets you easily fool yourself.
> Thinking about the “overall economy” increasingly means focusing on the spending of the rich, and ignoring the poor and struggling. A consequence of increasing inequality is the rich make up more and more consumer spending.
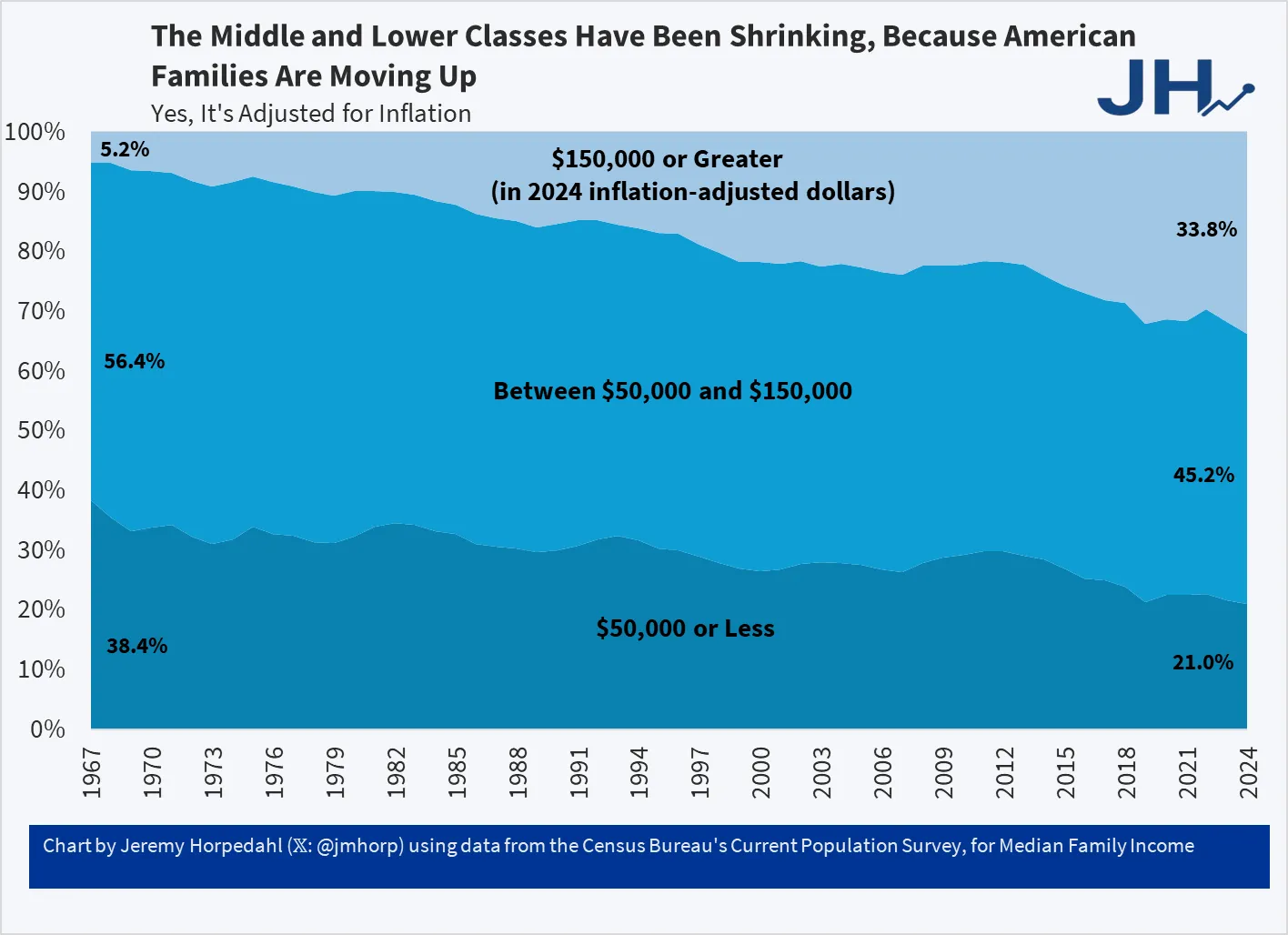
It means increasingly focusing on the spending of the rich, because the population is increasingly richer. Proportion of families making more that 150k (in 2024 dollars) has gone from 5% in 1967 to 33% in 2024, while both middle class (50k-150k) and poor (<50k) have decreased. [1]
Great example. The population as a whole is richer like you say, and also the richest 10% account for half of consumer spending, compared to 36% 30 years ago. [1] So yes, consuming spending has become more of a metric of the wealthy’s spending habits.
No single metric tells the whole story, and by taking them in isolation it’s quite easy to lose the forest for the trees.
On the bright side, I do think at some point after the bubble pops, we’ll have high quality open source models that you can run locally. Most other tech company business plans follow the enshittification cycle [1], but the interchangeability of LLMs makes it hard to imagine they can be monopolized in the same way.
> …lurked for years and even decades. Heartbleed comes to mind.
I don’t know much about Heartbleed, but Wikipedia says:
> Heartbleed is a security bug… It was introduced into the software in 2012 and publicly disclosed in April 2014.
Two years doesn’t sound like “years or even decades” to me? But again, I don’t know much about Heartbleed so I may be missing something. It does say it was also patched in 2014, not just discovered then.
This may just be me misremembering, but as I recall, the bug of Heartbleed was ultimately a very complex macro system which supported multiple very old architectures. The bug, IIRC, was the interaction between that old macro system and the new code which is what made it hard to recognize as a bug.
Part of the resolution to the problem was I believe they ended up removing a fair number of unsupported platforms. It also ended up spawning alternatives to openssl like boring ssl which tried to remove as much as possible to guard against this very bug.
I have Kodi running on a raspberry pi plugged into my Google TV. The Jellyfin plugin for Kodi works flawlessly so far for me. It’s just great! Sure if I could put Jellyfin directly on the TV, that would save me the RPi. But not a big deal for me.
Tbh I can imagine this catching on if one of the big cloud providers endorses it. Including hardware support in a future version of AWS Graviton, or Azure cloud with a bunch of foundational software already developed to work with it. If one of those hyper scalers puts in the work, it could get to the point where you can launch a simple container running Postgres or whatever, with the full stack adapted to work with CHERI.
CHERI on its own does not fix many of the side-channels, which would need something like "BLACKOUT : Data-Oblivious Computation with Blinded Capabilities", but as I understand it, there is no consensus/infra on how to do efficient capability revocation (potentially in hardware), see https://lwn.net/Articles/1039395/.
On top of that, as I understand it, CHERI has no widespread concept of how to allow disabling/separation of workloads for ulta-low latency/high-throughput/applications in mixed-critical systems in practical systems. The only system I'm aware of with practical timing guarantees and allowing virtualization is sel4,
but again there are no practical guides with trade-offs in numbers yet.
I think there is an important difference here from both Option<T> and Result<T, E>: the C3 optional doesn’t allow an arbitrary error type, it’s just a C-style integer error code. I think that makes a lot of sense and fits perfectly with their “evolution, not revolution” philosophy. And the fact that the syntax is ‘type?’ rather than ‘Optional<type>’ also eases any confusion.
{kind=link}
reply