Indeed. The problem with most AI research today is they simply do trial and error with large amounts of compute. No room for taking inspiration from nature, which is requires more thought and less FLOPS.
If by popular fantasy you mean replicating the functional profiles of the visual and language cortex of the brain, then yes. These ideas in neuroscience are popular, but not fantasy. I encourage you to read up on functional organization in the brain, it's very fascinating.
> it’s not scientifically useful
Having structured weights in GPTs enables us to localize and control various concepts and study stuff like polysemanticity, superposition, etc. Other scientific directions include sparse inference (already proven to work) and better model editing. Turns out, topographic structure also helps these models better predict neural data, which is yet another direction we're exploring in computational neuroscience.
I love the paper - don't read into the negative comments. I find that a lot of online feedback (more so on Reddit and much less so on HN (usually)) tends to be opinionated and misinformed by quite a bit these days. Fantastic work and fantastic read.
I probably came in too hot on that (dealing with some personal stuff). Although I disagree with purported the impact of the paper, I don’t think this is fundamentally incorrect or bad science and I wish you the best on future research.
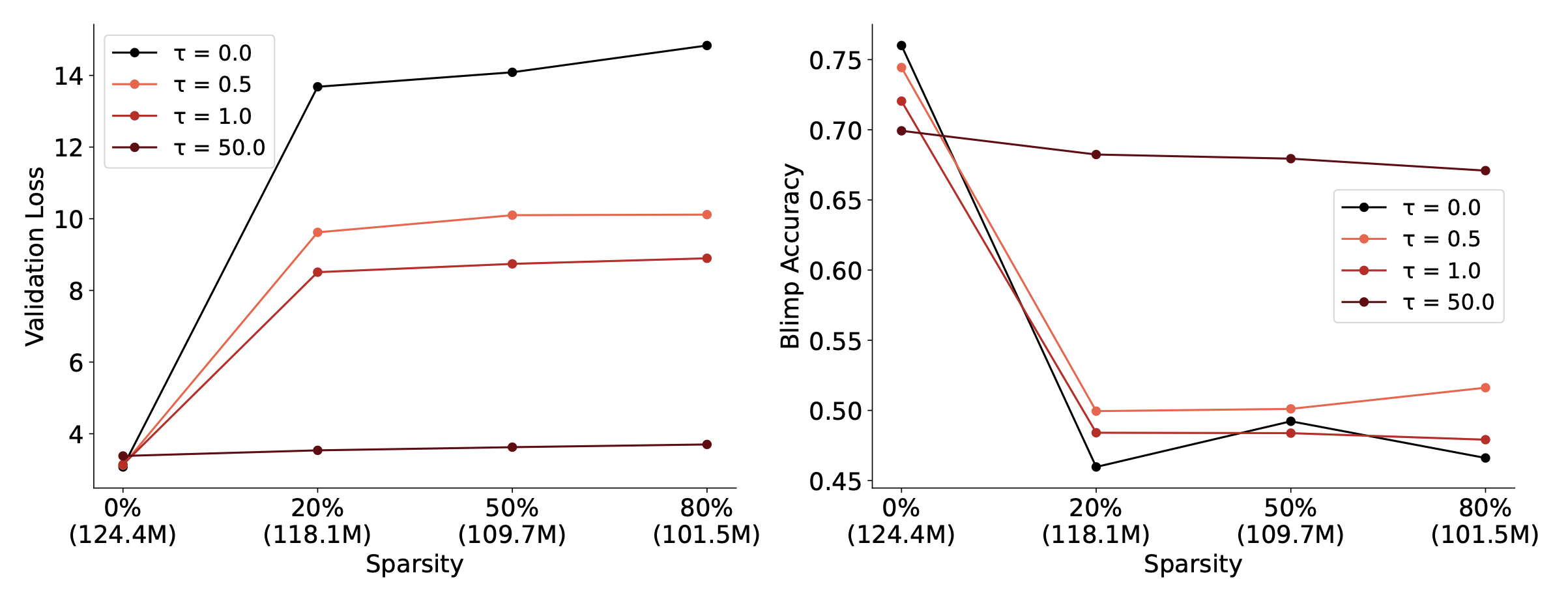
It is indeed brain-like in a functional way. Topographic structure is what enables the brain to have low dimensionality and metabolic efficiency. We find that inducing such structure in neural nets made them have significantly lower dimensionality and also more parameter efficient (After training, we could take advantage of the structure to remove ~80% of the weights in topographic layers without sacrificing performance)
>After training, we could take advantage of the structure to remove ~80% of the weights in topographic layers without sacrificing performance
This is really interesting to me. Is it that the structure clustered the neurons in such a way that they didn't need to be weighted because their function were grouped by similar black box properties?
> Is it that the structure clustered the neurons in such a way that they didn't need to be weighted
Yep. Because of the structure, we did not have to compute the output of each weight column and simply copied the outputs of nearby weight columns whose outputs were computed.
Yep. That is exactly the idea here. Our compression method is super duper naive. We literally keep every n-th weight column and discard the rest. Turns out that even after getting rid of 80% of the weight columns in this way, we were able to retain the same performance in a 125M GPT.
Indeed. What's cool is that we were able to localize literal "regions" in the GPTs which encoded toxic concepts related to racism, politics, etc. A similar video can be found here: https://toponets.github.io
My understanding coming from mechanistic interpretability is that models are typically (or always) in superposition, meaning that most or all neurons are forced to encode semantically unrelated concepts because there are more concepts than neurons in a typical LM. We train SAEs (where we apply L1 reg and a sparsity penalty to “encourage” the encoder output latents to yield sparse representations of the originating raw activations), to hopefully disentangle these features, or make them more monosemantic.This allows us to use the SAE as a sort of microscope to see what’s going on in the LM, and apply techniques like activation patching to localize features of interest, which sounds similar to what you’ve described. I’m curious what this work means for mech interp. Is this a novel alternative to mitigating polysemanticity? Or perhaps neurons are still encoding multiple features, but the features tend to have greater semantical overlap? Fascinating stuff!
Was it toxicity though as understood by the model, or just a cluster of concepts that you've chosen to label as toxic?
I.e., is this something that could (and therefore, will) be turned towards identifying toxic concepts as understood by the chinese or us government, or to identify (say) pro-union concepts so they can be down-weighted in a released model, etc?
We localized "toxic" neurons by contrasting the activations of each neuron for toxic v/s normal texts. It's a method inspired by old-school neuroscience.
The motivation was to induce structure in the weights of neural nets and see if the functional organization that emerges aligns with that of the brain or not. Turns out, it does -- both for vision and language.
The gains in parameter efficiency was a surprise even to us when we first tried it out.
1. Significantly lower dimensionality of internal representations
2. More interpretable (see: https://toponets.github.io)
> 7B model down to 6B
We remove ~80% of the parameters in topographic layers and retain the same performance in the model. The drop in parameter count is not significant because we did not experiment with applying TopoLoss in all of the layers of the model (did not align with the goal of the paper)
We are currently performing those strong sparsity experiments internally, and the results look very promising!
{kind=link}